Keeping secrets secret
Introduction
Software development is often seen as a blend of engineering and art — a creative process where developers work within the boundaries of project requirements, timelines, technological limitations, and team capacity. The goal? To produce human-readable code that, through various transformations, solves a specific problem.
From a business standpoint, software is primarily judged by its functionality and reliability. Metrics like maintainability, cleanliness, and security frequently take a back seat. However, neglecting these aspects, particularly security, accumulates technical debt—a silent burden that often only becomes apparent when it’s too late.
In the realm of security, this issue is particularly pressing. Security debt doesn’t give immediate warning signs. It’s a ticking time bomb that may go unnoticed until a breach or vulnerability makes its presence painfully clear.
So, what is the industry’s answer to this? “Shift left.” It’s a buzzword you’ve probably heard at conferences and in thought leadership pieces. The idea is straightforward: address security issues as early as possible in the Software Development Lifecycle. But in practice, integrating security into the early phases of software design is easier said than done.
This article focuses on a specific aspect of designing security into software — handling secrets. Secrets are everywhere in modern applications, whether they’re used to connect to databases, access third-party APIs, or authenticate with cloud services. Unfortunately, handling secrets is left for developers to figure out on their own without proper guidance, tools, or understanding of the security implications.
Here’s how the problem typically unfolds: a developer, working under time pressure, integrates an SDK to connect a service. They find an example snippet of connection code (or generate it with AI) and paste it into the codebase. These examples are designed for simplicity and clarity, often embedding connection credentials directly in the code. Without second thoughts, this practice makes its way into production.
Is this the developer’s fault? Not entirely. Developers are not security experts, and they rely on what’s provided — documentation, examples, and tooling. If the sample code suggests embedding secrets directly, they follow without second thoughts. Through countless source code reviews, I’ve noticed that secrets management is rarely top-of-mind for developers juggling competing priorities.
As a developer myself, I empathize with these challenges. Security often feels like an external pressure, a “nice-to-have” rather than a “must-have.” But this mindset needs to change. In this article, I aim to bring a software-focused view on the secret management solutions. We’ll explore practical strategies for securely handling secrets, evaluate various methods and discuss some challenges that may arise.
(Note: The perspectives shared in this article are my personal views and should be interpreted as such.)
Secrets handling
Handling secrets securely is a complex challenge with no one-size-fits-all solution. The approach varies depending on the deployment environment — secrets for an application running on a bare-metal server are managed differently than those for a serverless application hosted by a cloud provider. Even among cloud vendors, secret management practices can differ significantly. Additionally, the type of secret matters; for instance, some secrets require frequent rotation to maintain security, while others are designed to be long-lived.
Fortunately, there are common patterns that can be applied across many scenarios. In the following sections, I will outline the different types of secrets and provide practical methods for managing them effectively.

Types of secrets
Identifier and password
What is the easiest way to protect a valuable resource? Introduce a password. But it is not good idea for everyone to use the same password. So let’s add an identifier to the password, so we can distinguish between users. An identifier and password pair is probably the oldest and most common mechanism. You can find it in almost every system that requires authentication, and even if stronger methods are present, this one is still used for fallback.
It’s simple, easy to implement and understand, and widely supported. Usable for both human and machine authentication.
The identifier (e.g., username, email, account number) is typically a publicly known value that is used to locate user entry. Then the secret part, e.g., password, known only to server and client and therefore can be used to authenticate.
Examples:
- username and password (any user-based authentication)
- client_id and client_secret (OAuth2)
- role_id and secret_id (Hashicorp Vault AppRole)
Tokens
What if the communication is server-to-server? Then, identifier and secret can be in one value - token. The identifier and secret can be combined into a single value—a token. Tokens come in various forms: they can carry information (e.g., JWT), be time-limited (e.g., TOTP), or be opaque (e.g., API key). Typically, the tokens requiring secure handling are bearer tokens that are non-expiring and used for API access.
Bearer tokens mean the token alone is sufficient to authenticate; no additional information is needed. This also means that anyone, including an attacker, can use the token if they obtain it. Non-expiring tokens remain valid until explicitly revoked. If such a token is leaked, an attacker can continue using it until it is revoked.
Developers typically create an account with a third-party service, generate a token, and use this token in their application. The token is then attached to each request made by the application.
Examples:
- API key
1
AIzaSyDaGmWKa4JsXZ-HjGw7ISLn_3namBGewQe
- JWT token
1
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJDeWJlclNvdXAiLCJpYXQiOjE3MzM2MjczMTQsImV4cCI6MTc2NTE2MzMxNCwiYXVkIjoid3d3LnJlYWRlci5jb20iLCJzdWIiOiJhd2Vzb21lQGV4YW1wbGUuY29tIiwiR2l2ZW5OYW1lIjoiQXdlc29tZSIsIlN1cm5hbWUiOiJHdXkiLCJFbWFpbCI6ImF3c29tZUBleGFtcGxlLmNvbSJ9.tCdcOT4NBelKf7Tmi88COsFh5Tf6_KMlJAg_danXs8E
Cryptographic keys
Secrets aren’t just for authentication—they’re also critical for cryptographic operations. Whenever an application needs to encrypt, decrypt, or sign data, it relies on a key. Whether it’s using symmetric or asymmetric cryptography, and regardless of the algorithm, these keys are considered secrets and must be carefully protected within the application.
From a developer’s perspective, implementing cryptographic operations can be a headache. Different programming languages and libraries provide inconsistent interfaces, and documentation is often unclear. To make matters worse, the way keys are formatted and represented varies widely. For example, some libraries expect keys in base64 format, while others require them to be stored in a keystore or loaded from the file system. This inconsistency leads to confusion, mistakes, and often delays in implementation.
Examples:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
-----BEGIN RSA PRIVATE KEY-----
MIICXAIBAAKBgQDLKHCTCfANm8BbfrEG1U5jknlPqK/HzT2vK5uzzHuBQFfQRUOb
zuv39apu15AjA4FOYtWQtDEGabjGgkgMvneRS8PVD+pOYr/KdW/g8Ldjf4DlGPAX
NXuuSm6J0rWcx298AQEE7MRWHzZmx4+HD0Kl7DtpLpZQbkd26NbDzxHqVQIDAQAB
AoGAQ0SMoeM0fQ0JUEJO03hlkEq7qEiui3XF6u6Bi7M1YcKwUOHeVQTa1Sue1zzB
GRbcBdxr4pIHeZwf9nrE6JNYe0hTSZA8FzUkK+tzjHf0dyIvNrSRZSbUUgixOY9y
4PbndVQB2mvZf/c3uXV0F1UPVx8yUYPvXbrfAGtdd3eKFYECQQDyJG1eBSqtV9s4
Hn2ajEfqh8n+fsM3/dVwy/8ucAt8bX9+ki0qOSVcHUopLrzubuCqFZAheUYoaZvA
SgBqNFsJAkEA1sjcon3xoGoLptaynq/QVNzgWwsMo0vRDVDIo9eEoBWdPchg9xz1
lCYUrVGV4GH+8MbxR54I+PClSbOQ+/5L7QJAaGjiq87ohxRCF6G2IUTp4awpok5A
mU0fkuKzpu9zVHTWq9oWFYXMoTqT9swLdXhj8ZMYsgZcBSL8oN6H7UOkGQJAAnHi
4Q6h83uBinKjMd86ddzVyPOFP06boJUs04Ceh9v3ID7pq6ZuvTL5xUdKd3VmG4OI
N5J686p5ly8uFVA9uQJBAMbn43f943l5zJIrCVFR13+eSBKpWz1sYiKHQZSF/ZuS
OqoKKoknYBUjYRF/rusSadh/e7PMn4Dcc1W32SviYwU=
-----END RSA PRIVATE KEY-----
Rotation & dynamic secrets
Some secrets are designed to last a long time—they remain valid until explicitly revoked. In some systems, this might be fine if the risk is low. But for others, it’s a legacy approach that fails to account for modern security threats.
From a developer’s perspective, static secrets are incredibly convenient. You configure them, deploy your application, and forget about it. From a security perspective, though, this approach is a disaster. If a static secret gets leaked—say, it’s accidentally committed to source code—it’s game over. Anyone who gets their hands on it can use it. Worse, the resource server can’t distinguish between a legitimate request from the secret’s owner and a malicious request from someone who stole it.
One way to reduce this risk is by rotating secrets. This involves periodically updating the secret on both the client and server sides. It’s a great idea in theory, but in practice, it raises some tough questions: How do we handle secret rotation in our application?
“IDK, we just have one static file with all the secrets saved on disk,” says the developer.
Great, so implementing rotation isn’t going to be simple. And then the plot thickens:
“We need to implement dynamic secrets for database access“ announces the manager, reading from a security audit report.
“Dynamic secrets? What are those?” asks the developer.
And thus begins the next chapter of the developer’s security saga. Dynamic secrets are generated on the fly—created only when an application or user needs access to a resource. Unlike static secrets, they’re valid only for a short period of time and don’t need to be stored long-term.
Sounds promising, right? But wait… How are these secrets generated? Who’s responsible for the process? And how do we verify the requester? We will see that later.
Example:
- Hashicorp Vault dynamic secrets
- AKeyless dynamic secrets

Solutions
Let’s explore the different ways to manage secrets in an application. We’ll start with the simplest and most obvious solutions (the ones you definitely shouldn’t use) and gradually move toward more advanced and secure approaches.
As you’ll notice, the level of effort required to implement a solution often goes hand in hand with the level of security it provides. That’s why it’s always about finding the right balance between how secure your application needs to be and how much effort you’re willing to invest in achieving it.
Hardcoded secrets
A quick side project is nearly done, running smoothly on a local machine. It connects to a cloud database using a secret. Since it’s just a simple, one-file proof of concept, the developer hardcodes the secret directly into the code. No big deal, right? But then the team decides to use it for an internal project, so the developer pushes the code to a repository. And just like that, the secret is in the repo.

This scenario is as old as software development itself. The moment a file leaves the developer’s machine, any secrets in it should be considered compromised. Whether it’s pushed to a Git repository, shared via email, sent on Slack, or uploaded to cloud storage, the secret is now effectively in the wild.
How often does this happen? All the time. According to the GitGuardian report, over 12 million secrets were found in public Git repositories in 2023 alone.
Every Application Security guideline tells you: don’t store secrets in your code. Yet it still happens even to the best of us, simply because it’s quick, easy, and convenient.
So what should I do instead? - asks the developer.
We will see better options in the next sections, for now let’s look what can be done to prevent hardcoded secrets.
My advice? Automation, automation, and more automation. The earlier we can detect secrets, the better. Tools like pre-commit Git hooks, such as git-secrets, can catch issues before the code even makes it to the repository. However, since developers can bypass these checks, it’s essential to have similar scanning in place in the CI pipeline (e.g., TruffleHog).
As much as I love automation, I’ll admit it’s not perfect—it won’t catch everything. That’s why manual code reviews are still important. And let’s be honest, developers are human. If they’re not given clear instructions, they’ll often take the easiest path. So, instead of just expecting them to get it right, we need to make sure they’re trained properly first.
Examples:
(Please don't do it)
1
2
3
4
from Crypto.Cipher import AES
obj = AES.new('secret', AES.MODE_CFB, 'ivvalue')
message = "Seriously, don't do it."
ciphertext = obj.encrypt(message)
Evaluation
| Effort | Almost none |
| Security | None |
| Recommendation | Big no no |
Environment variables
So, what’s the first step to keep secrets without hardcoding them? The typical approach is to put a placeholder in the code and resolve the actual secret later. But where do we get the secret from?
The obvious first choice is environment variables.
These are key-value pairs available when the application runs. They come from the execution environment, whether it’s the operating system, a container, or a cloud provider. This way, secrets don’t need to be packaged with the code but can instead be referenced in the code and resolved at runtime.
Sounds like a great solution, right? It’s definitely better than hardcoding secrets. It shifts the responsibility from the developer to someone else—like the system administrator. But let’s dig into where the secret actually lives now.
In the case of a simple VM, the environment variable needs to be set in the VM OS for the application to access it. This can happen when the application starts (e.g., in a bash script) or in the user configuration running the app.
In containerized environments, like Kubernetes, environment variables are often set in the deployment configuration. And in serverless environments, like AWS Lambda, you can set environment variables directly in the function configuration.

If access to the environment is well protected with MFA, and everything’s logged and monitored, then maybe this is secure enough for your risk appetite. But let’s be real — manual configuration comes with its own set of headaches. Copying configurations, injecting secrets from a password manager, and switching values between environments, among others, can easily result in late-night, stressful, and hours-long deployment processes So, let’s bring in some DevOps trends like GitOps and Infrastructure as Code (IaC). This means your infrastructure is defined as code, and guess where that code is stored? In a repository.
So, does this mean our precious secrets are back in the repository? Have we just swapped one repo for another?
Well, if you stop thinking right here, then yep, that’s exactly what’s happened!
Examples
1
2
3
const user = process.env.USERNAME;
const password = process.env.PASSWORD;
const apiKey = process.env.API_KEY;
Evaluation
| Effort | Minimal |
| Security | Better than hardcoded passwords, but still poor |
| Recommendation | If you can’t do any better |
Files
Not too far from environment variables are files—config files, properties files, JSON files, YAML files, and so on. These are often used to store application settings, and sometimes, the secrets sneak in there too. Usually, these files are kept next to the application with at least read permissions. When the application starts, it reads the file and loads the secrets into memory.
Sometimes, config files don’t directly hold secrets but rather point to environment variables where the secrets live. This means the secret is resolved at runtime, and the config file doesn’t need to actually store the sensitive data. This gives developers flexibility to locally work with typically single configuration file without setting up the environment, whereas the environment version of the file can use environment variables.
So, is this really much different from environment variables? Not really. It’s just another way to store the secret within the environment.
But let’s again add GitOps into the mix, and things might get a little worse. For instance, if your secrets are tucked into config files that are versioned in Git, you might just find yourself back at square one with the problem of hardcoded secrets again.
Examples
1
2
3
serviceUrl: https://example.com
username: user
password: secret
1
2
3
serviceUrl: https://example.com
username: user
password: ${SECRET_PASSWORD}
Evaluation
| Effort | Minimal |
| Security | Better than hardcoded passwords, but still poor |
| Recommendation | If you can’t do any better |
Vaults
What if you could offload the responsibility of storing and controlling access to secrets to a specialized service? Well, that’s exactly what vaults are for.
Vaults are centralized services designed to securely store secrets—encrypted, of course—and provide fancy features like advanced access control and auditing. Instead of having secrets sitting right next to your application, now your app has to go ask the vault for them.
Just like with environment variables, the application uses placeholders for the secrets and resolves them at runtime, but now it’s all handled by the vault.
The best part? Vaults give you total control. You get a clear overview of which secrets exist, who can access them, and when they’ve been accessed. You can set up complex policies to make sure only certain applications get to touch certain secrets. Plus, you can decide how long an app can have access to a secret before you revoke it.

Examples
- Hashicorp Vault
- AWS Secrets Manager
- Azure Key Vault
- GCP Cloud Key Management
Evaluation
| Effort | Medium |
| Security | Ain’t too bad |
| Recommendation | It is the minimum you should do |
Secret Zero Problem
There is one question that is not answered yet. We can’t give everyone access to the vault, so how does an application authenticate to it?
Good question! Unfortunately, the straightforward answer might not be all that satisfying.
The simplest approach is to use credentials to authenticate to the vault. But wait—where does the application store those credentials? And just like that, we’ve stumbled into a chicken-egg problem: to access secrets, you first need a secret.
There’s even a name for this tricky situation: the Secret Zero Problem.
“What’s the point of having a vault if you still need a secret to access it?” asks the Developer.
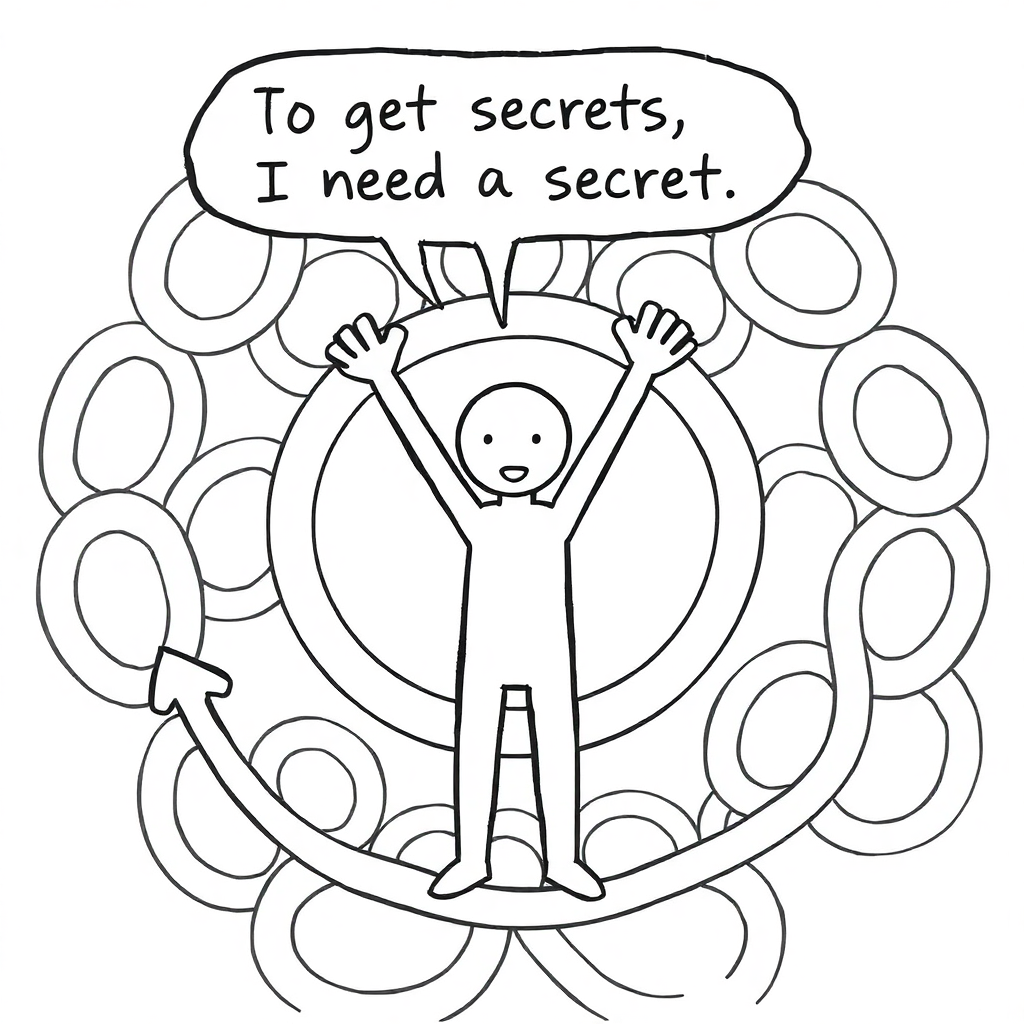
A fair question, and one that highlights the Secret Zero Problem. No matter how you slice it, there’s always a secret somewhere. But here’s the key: while we can’t eliminate the problem entirely, we can manage it better by putting stricter controls on the secret used to access the vault.
For example, in a Kubernetes setup, the secret to access the vault might only be injected into pods that are signed and verified by our CI pipeline. This ensures the secret is tightly scoped and only accessible where it’s truly needed.
What about the vault itself? At the end of the day, it’s just another app, usually with an admin or root account that has all the power. But vaults are built with strong security features to keep things under control. For example, many vaults come with sealing by default. When the vault restarts, it stays locked until someone unseals it with a special secret. Using just one secret would be risky, but access can be configured to split the secret into pieces, and then shared among several people. That way, no one person can unlock the vault by themselves, making it much harder for anyone to break in.
So yes, secrets are unavoidable. But by using dedicated tools like a vault, we gain the ability to apply robust controls, reduce exposure, and make the problem far more manageable.
Cloud Identity
Let’s take a closer look at how an application can securely access other services, like vaults. Traditionally, this trust is built by having the service generate a secret and then handing it over to the application. But what if we rethink this model and introduce a third party to handle the trust?
We already see similar approaches working well for users with technologies like OAuth2, SAML, and OpenID Connect. Interestingly, cloud providers have extended this concept to applications too.
Here’s how it works: when an application is deployed in a cloud environment, the cloud provider can assign it an identity. Services like vaults then trust the cloud provider and grant access to the application based on this identity. The proces eliminates the need for the application to handle static secrets directly.

But how does this actually work for a developer?
In practice, the application requests an identity JWT token from a dedicated cloud endpoint available only to running applications. This means there’s no need to store or configure secrets in environment variables or files. It’s a clean, secure solution that simplifies secret management.
Once authenticated using the cloud-provided identity, the application can access the secrets it needs from the vault.
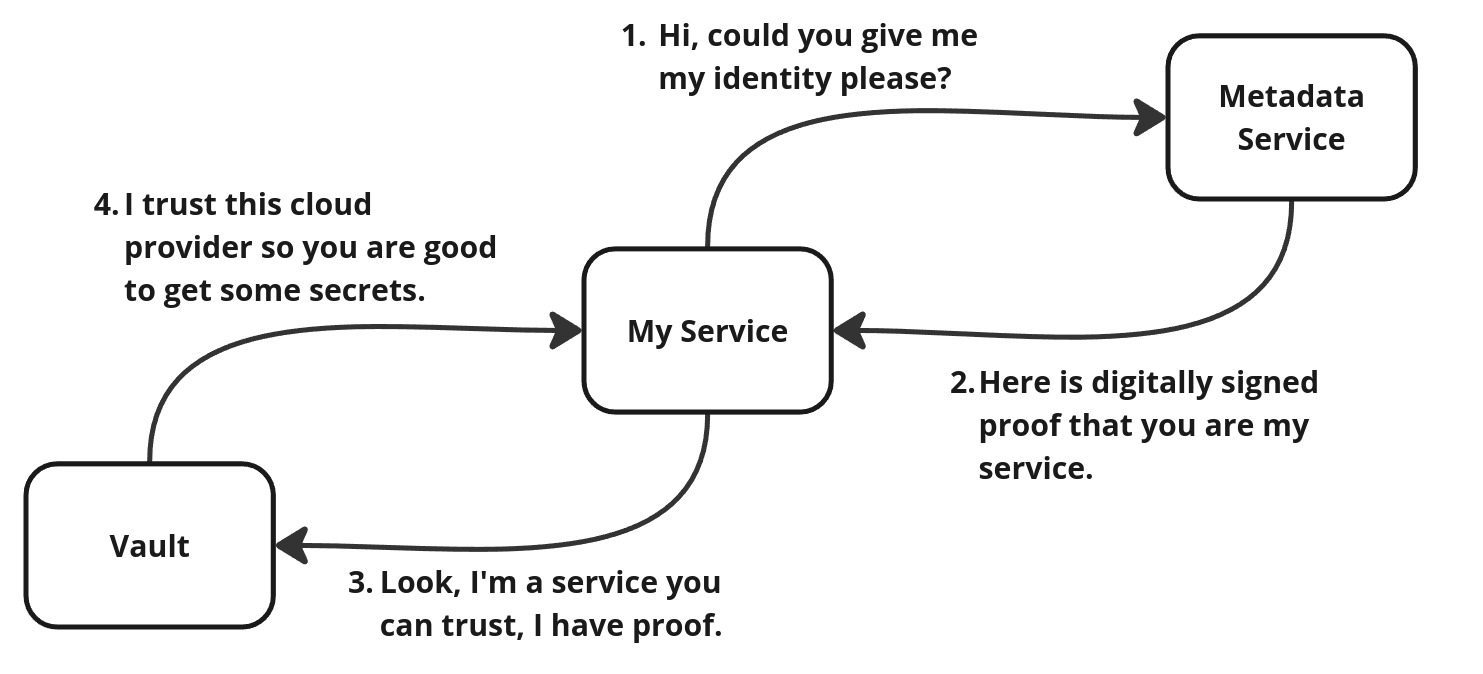
“With cloud identity, we finally don’t have any secrets” says developer.
Well, to be precise, we haven’t eliminated the Secret Zero Problem entirely. Instead, we’ve shifted the responsibility to the cloud provider—a tradeoff that often aligns well with most organizations’ risk tolerance.
Evaluation
| Effort | Medium |
| Security | Cybersecurity potato stamp of excellence |
| Recommendation | Should be your goal |
Crypto as a Service
So now the question is: can we do any better? Secrets are no longer hardcoded, they’re not in the environment, they’re not in the files—they’re in the vault, and authentication to the vault is based on cloud identity. Pretty good, right?
Well—yes and no.
Let’s get a bit paranoid. What if the application is compromised, and an attacker can execute commands within the application context (e.g., remote code execution)? While there are no secrets in the environment, the running application has the secrets loaded in memory. If the attacker can dump the memory, they can retrieve the secrets—and this is not a particularly difficult thing to do.
So, what can we do? Actually, we can raise the security bar a bit higher. Imagine you have a secret used for encrypting data before it’s saved to the database. You need the secret to run the encryption algorithm, but the algorithm doesn’t necessarily need to run in the application itself.
Just as we delegated secret storage and access control to the vault, we can also delegate cryptographic operations. There’s even a term for this: Encryption-as-a-Service. The same approach applies to digital signatures and other cryptographic operations.

So in this model, the application does not have to have the secret to run the cryptographic operation. Again, the application can be authenticated to the service using cloud identity. This way even if attacker is able to dump the memory, he won’t get the secret.
But isn’t attacker able to request an encryption or signature operation? - asks the developer.
Well as long as the attacker has the access to environment, he is.
But this is much better than attacker stealing the secret. Again we do not eliminate the risk, but we reduce it to acceptable level. In this model we can introduce additional controls, e.g., rate limiting, behavior analysis, etc.
Ok, but how to do it? Our app uses a local encryption SDK. - says the developer.
Well, this is a good question. Of course cloud solutions have an SDK for that but the challenge is how to integrate it with the exising code base. Typically cryptographic operations are either provided as native language functionality or libraries. Sometimes it might be a significant development effort to replace the existing code with the external cryptographic service.
Examples
This example shows a simple encryption API from Azure Key Vault. An application can call this API to encrypt the data. In response, the application gets the encrypted data, but the secret is never exposed to the application.
1
2
3
4
5
6
7
8
9
10
11
12
13
Request:
POST https://myvault.vault.azure.net//keys/sdktestkey/f6bc1f3d37c14b2bb1a2ebb4b24e9535/encrypt?api-version=7.4
{
"alg": "RSA1_5",
"value": "5ka5IVsnGrzufA"
}
Response:
{
"kid": "https://myvault.vault.azure.net/keys/sdktestkey/f6bc1f3d37c14b2bb1a2ebb4b24e9535",
"value": "CR0Hk0z72oOit5TxObqRpo-WFGZkb5BeN1C0xJFKHxzdDCESYPCNB-OkiWVAnMcSyu6g2aC8riVRRxY5MC2CWKj-CJ_SMke5X2kTi5yi4hJ5vuOLzmg_M6Bmqib7LsI-TeJHr9rs3-tZaSCdZ2zICeFWYduWV5rPjTnAD98epTorT8AA1zMaYHMIhKpmttcj18-dHr0E0T55dgRtsjK04uC3FlRd3odl4RhO1UHAmYpDd5FUqN-20R0dK0Zk8F8sOtThLhEmuLvqPHOCUBiGUhHA4nRDq1La4SUbThu2KMQJL6BbxxEymuliaYcNNtW7MxgVOf6V3mFxVNRY622i9g"
}
Source: Azure Key Vault
Evaluation
| Effort | Significant |
| Security | Security nirvana |
| Recommendation | Do it if you can |
Summary
Secrets are an unavoidable part of application development, but the way we handle them makes all the difference. Do you feel comfortable with a teammate who hardcodes API keys and waves it off with, “It’s fine; it’s only for testing!”? Or are you ready to explore better options for managing secrets securely? The right solution could be as close as the next library or tool, ready to transform how your team protects sensitive information.
By choosing a secure approach from the start (as the “shift left” principle recommends), you can save yourself the hassle of reworking your code later. A little effort upfront goes a long way in keeping your application safe and future-proof.
I hope this article gave you some useful ideas on how to handle secrets securely and save yourself from future headaches (and embarrassing leaks).